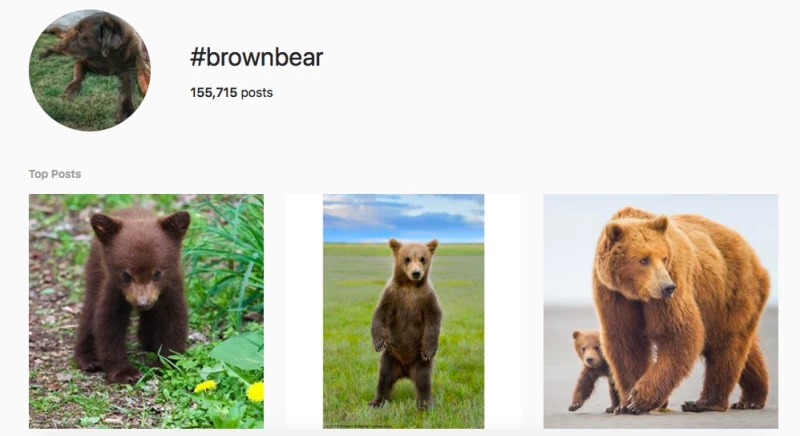
Instagramのハッシュタグを考えてみましょう。Facebook傘下のこのプラットフォームに写真を投稿する際に、ハッシュタグを付けることができます。例えば、#love、#fashion、#photooftheday といったハッシュタグです。これらは昨年のハッシュタグのトップ3でした。これらのタグは抽象的な概念を表していますが、#brownbear のように、より具体的な説明を表すものもたくさんあります。当然のことながら、#brownbear にはクマの写真がたくさん投稿されています。
しかし、ハッシュタグは、何百万枚もの #travel 写真を一か所で見るための便利な手段である一方、Facebook は、ラベルの付いた写真を使用して、別のことを行いました。画像認識ソフトウェアをトレーニングするのです。これは、コンピューターに画像内のものを認識させるコンピューター ビジョンと呼ばれる一種の人工知能です。
実際、彼らは約35億枚のInstagram写真(公開アカウントから)と17,000個のハッシュタグを使用して、これまで作成した中で最高のシステムだというコンピュータービジョンシステムをトレーニングしました。
FacebookのCTO、マイク・シュローファー氏は本日、同社の開発者会議F8でこの研究を発表し、その結果を「最先端」と呼んだ。
監督不足
これがなぜ興味深いアプローチなのかを理解するには、人工知能システムの「完全教師あり」学習と「弱教師あり」学習の違いを理解することが重要です。コンピュータービジョンシステムは、物体を認識するように学習させる必要があります。例えば、「クマ」とラベル付けされた画像を見せれば、新しい写真の中にクマだと判断した画像を識別するように学習できます。研究者が人間が注釈を付けた写真を使用し、AIシステムがそこから学習できるようにすることを「完全教師あり」学習と呼びます。画像には明確なラベルが付けられているため、ソフトウェアはそこから学習できます。
「これは本当にうまくいきます」と、Facebookの応用機械学習グループのコンピュータービジョン責任者であるマノハル・パルリ氏は語る。同グループは、Facebook AIリサーチという別の部門と共同でこの研究を行った。このアプローチの唯一の問題は、そもそも画像にラベルを付ける必要があることであり、これには人間の作業が必要になる。
「数十億枚ものラベル付き画像を扱うのは、もはや不可能になりつつあります」とパルリ氏は付け加える。人工知能の世界では、システムが学習できるデータが多ければ多いほど、一般的にシステムはより良くなる。そして、データの多様性も重要だ。AIシステムに結婚式の雰囲気を認識させるには、北米の結婚式の写真だけでなく、世界中の結婚式の写真を見せるべきだろう。
ここで「弱教師あり」学習が登場します。これは、AIに学習させる目的で人間がデータを注意深くラベル付けしていない学習です。そこで、何十億枚ものInstagramの写真が活用されるようになりました。これらのハッシュタグは、ラベル付け作業をクラウドソーシングする手段となります。例えば、#brownbearというタグは、類似の#ursusarctosというタグと組み合わせることで、クマの画像のラベルになります。Instagramユーザーがラベル付けをするようになったのです。
しかし、そのようなデータは乱雑で不完全であり、ノイズが多い。例えば、パルリ氏は、エッフェル塔の近くでInstagramの写真を撮った人が、その写真に「#cake」というタグを付けることはあっても、塔自体は写っていないと指摘する。このラベルは人間の文脈では意味を成すが、単純なコンピューターにとってはあまり役に立たない。また、ケーキが写っている誕生日パーティーのシーンに「#cake」というラベルが付けられない可能性もある。これは、コンピューターにデザートの見た目を学習させる際にも役に立たない。

とにかくうまくいった
しかし、最終的な結果は、元のデータにノイズがあったにもかかわらず、非常にうまく機能したとパルリ氏は言います。あるベンチマークで測定したところ、数十億枚ものインスタグラムの写真でトレーニングされたこのシステムは、平均で約85%の精度を示しました。パルリ氏によると、これはFacebookがこれまでに開発した中で最も強力なコンピュータービジョンシステムだそうです。
Facebookをご利用の方なら、アップロードした写真の顔を認識し、(うまくいけば)適切な名前でタグ付けすることを提案してくれることをご存知でしょう。これはコンピュータービジョン、つまり今回の場合は顔認識の一例です。しかし、Facebookはコンピュータービジョンを、顔以外にも、プラットフォーム上で禁止されている視覚コンテンツ(ポルノなど)などを識別するためにも活用しています。
パルリ氏によると、Instagramでトレーニングされたこの新しい技術は、サイトに掲載すべきではない写真に不適切なコンテンツが含まれている場合にフラグを立てるのに既に役立っているという。「不適切なコンテンツ」の認識に関しては、すでに「精度が大幅に向上している」とパルリ氏は述べている。
